Welcome to RQL's Blog!
Do Better Every Day!-
ERA5和ERA-interim差异
翻译自:https://www.ecmwf.int/en/newsletter/159/meteorology/global-reanalysis-goodbye-era-interim-hello-era5
2020年第一季度时,ERA5被发布,以替代自2006年开始发布的ERA-Interim。ERA5基于4D-Var data assimilation using Cycle 41r2 of the Integrated Forecasting System (IFS),该系统于2016年开始在ECMWF运行。
相比于ERA-Interim, ERA5的优势在于模式物理、动力核、数据同化的改进,且分辨率从ERA-Interim的79km提高到31km。此外,ERA5可以提供逐小时输出及一个不确定性估计。The uncertainty information is obtained from a 10-member ensemble of data assimilations with 3-hourly output at half the horizontal resolution (63 km grid spacing).且ERA5输出的气象变量更丰富,例如多了100m风。
现在已经到了逐步淘汰ERA-Interim的时候了,因为ERA-Interim使用几种新的重要观测数据的能力有限,越来越难以维持,也不会迁移到欧洲中期天气预报中心在Bologna的未来数据中心。
使用的观测数据
在ERA5中使用的观测数据从1979年0.75MB/day增长到2018年24MB/day。其中,卫星辐射是最主要的增长数据。2009年后的降水数据中还同化了雷达观测。
相比于ERA-Interim,ERA5利用all-sky方法同化对湿度敏感的卫星频道。这可以在多云和降水地区提供新的信息,也纠正了早期在多雨条件下辐射同化技术导致20世纪90年代全球海洋ERA-Interim异常降水的一个问题。
传统数据和卫星数据的特征描述、相互校准和处理的改进逐步改进了历史观测的质量,并扩大其地理和时间覆盖范围。ERA5利用了几个再处理的卫星数据集,这些数据来自欧洲、美国和日本的空间机构和研究所。其中包括大气运动风矢量;臭氧、无线电掩星和测高数据;来自散射计的土壤湿度和风数据;以及对海洋湿度敏感的卫星数据的SSMI记录。
ERA-Interim无法吸收来自最新卫星仪器的观测数据(例如IASI和CrIS的高光谱数据)和地表雷达数据。此外,由于某些仪器和通道的失灵,ERA-Interim使用的观测数据逐渐减少。ERA5还可以处理自2013年以来越来越多地被地面压力、高空风和温度数据所采用的BUFR格式。而ERA-Interim无法处理这种形式,因此,它所吸收的观测数量急剧减少。在2018年底,ERA5每天使用约2400万次观测,大约是ERA-Interim的5倍。总得来说,ERA5使用的观测数据比ERA-Interim多很多。
模型输入强迫
ERA5使用的模型输入强迫包括太阳总辐照度强迫、臭氧、温室气体和为世界气候研究计划(WCRP) CMIP5倡议开发的一些气溶胶,包括平流层硫酸盐气溶胶。这是对ERA-Interim的一个重大改进,例如,ERA-Interim没有考虑到主要火山爆发造成的平流层硫酸盐气溶胶。
海表温度(SST)和海冰覆盖的演变基于不同时期的若干产品:英国气象局哈德利中心的海温和海冰HadISST2产品,EUMETSAT OSI-SAF再分析海冰数据,以及英国气象局的海温和海冰OSTIA产品,该产品也用于ECMWF的业务预报系统。细节可以在Hirahara et al.(2016)中找到。使用这些数据的目的是产生一个合并的数据集:
- 在每个时刻都尽可能准确,
- 没有明显的不连续,
- 可以可靠地接近实时更新。
所有这些输入数据集每天都在变化。全球平均海温显示了20世纪70年代中期以来全球变暖的影响,以及El Niño事件(例如1997/98年和2015/16年)和大型火山爆发的影响。随着时间的推移,北极海冰总体上呈下降趋势,尤其是在夏季。
ERA5不确定性估计
再分析是将模式信息与观测信息混合在一起的数据同化系统的结果,可以提供随时覆盖全球的数据。再分析数据总体上比前卫星时代更准确,因为当时的观测相对稀疏。ERA5使用的10个集合的4D-Var系统提供了对数据不确定性的估计。这些估计取决于数据同化中使用的短期预测中与流体相关的不确定性。它们还很大程度上取决于观测覆盖范围。
提高天气和气候数据质量
从ERA5再分析开始的再预测显示,相比于ERA-Interim,在技术范围内增加了大约一天的提前预报天数。此时,可以更好地模拟热带气旋地中心气压和降水量。逐小时地时间分辨率使我们能够更精确地观察每日天气系统的演变。
-
Potential Vorticity
位涡的概念
Rossby于1930s年代提出位涡的想法,是希望得到一个与垂直涡度相关的、类似于位温一样的守恒量。这里的“垂直”是指垂直于分层界面。
这一想法是具有重要而深远的意义的。因为这一概念不仅适用于地球上的大气和海洋,也适用于太阳这一类恒星的辐射内部。它对于理解平衡流以及一系列基本的动力过程都很重要,例如Rossby波的传播与破碎及其对大气的影响、全球尺度的遥相关、急流self-sharpening等的反摩擦现象、气旋反气旋和风暴路径的生成、风的形成等等。

感觉位涡可以理解为等熵面间单位质量的涡度
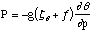
位涡是一个标量,是一个综合表征大气运动状态和热力状态的物理量,它的重要性在于绝热无摩擦运动中微团的位涡守恒,位涡守恒定理揭示了涡度变化是受到大气热力结构制约的。
位涡是由绝对涡度和静力稳定度两部分组成的,平流层和对流层顶及高空锋区附近的高位涡主要是因为温度垂直梯度很大,和涡度的大小无明显联系。
等熵面就是等位温面,等位温面向低纬倾斜
一般会以2PVU为对流层顶

平流层的位涡比对流层的位涡大很多(因为垂直温度梯度大)。相同高度下,高纬的位涡大于低纬地区(因为f)
位温随高度升高而增大,因此当等位温线上突时,表明此处位温小,对应温度小,偏冷
因为PV和位温都是随着高度的升高而增大。因此等PV面上的低位温表明此处等PV面下凹,有PV大值,对应气旋;高位温表明有反气旋
位涡的特点:
- Invertibility 可逆性或可反演性
- Material Invariance 物质不变性(守恒性)
- Impermeability 不可穿越性
位涡的守恒性
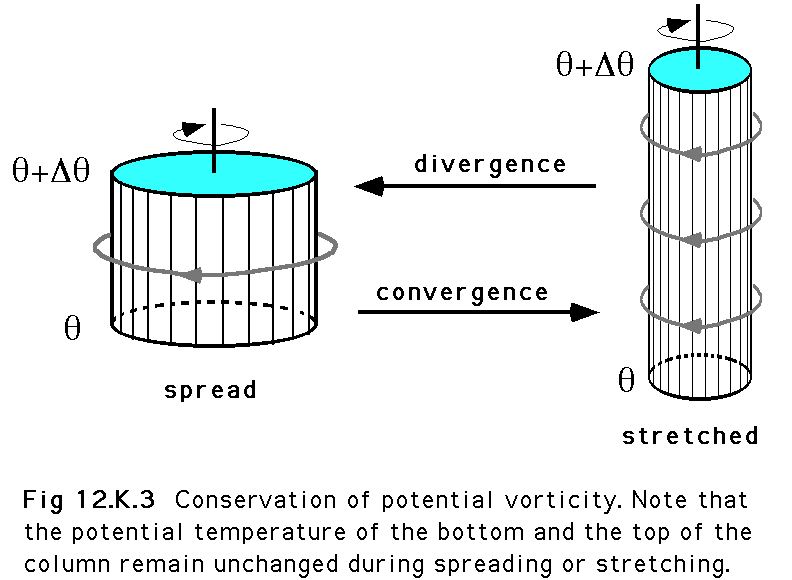
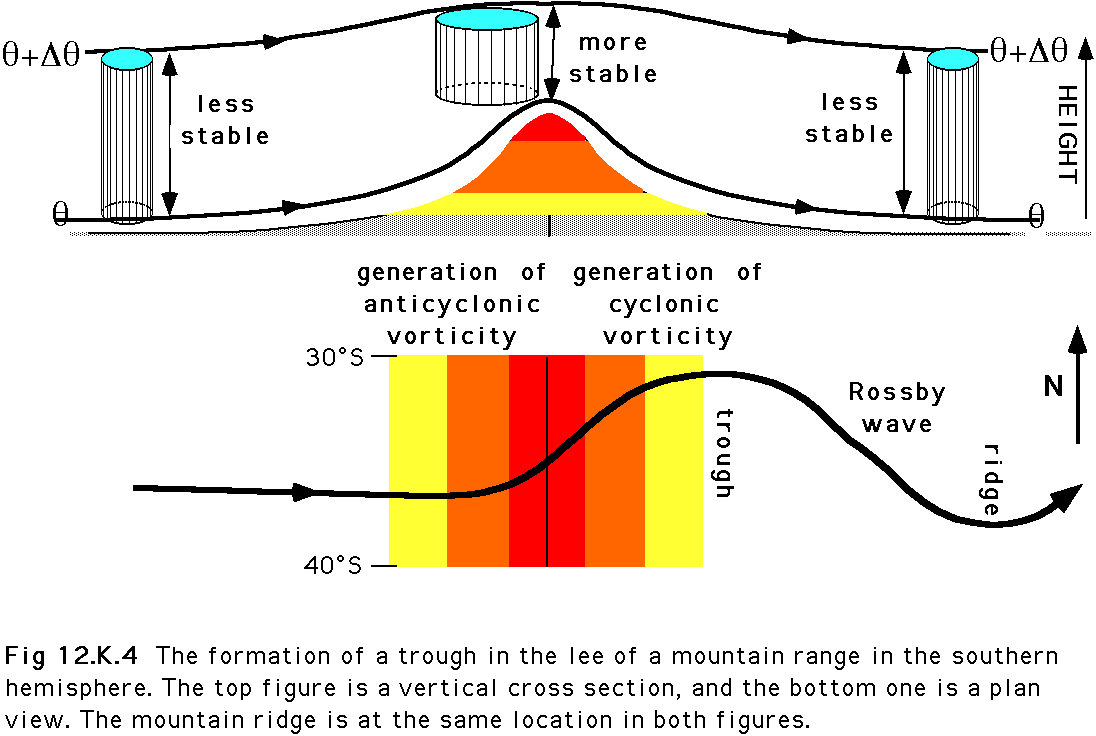
空气微团的位涡具有守恒性,只有在非绝热加热和摩擦的作用下能使位涡发生变化. 位涡守恒状况下,当空气团被压缩时,其绝对涡度减小;当空气团被拉伸时,其绝对涡度增大.可用这个解释山地背风波现象.
同样,当辐散导致空气微团水平膨胀时,绝对位涡减弱.

几种位涡公式
Rossby的位涡公式(1936年):对于无耗散流,位涡守恒。因此当两个等熵面远离时,绝对涡度的垂直分量通过涡旋拉伸而增加;当等熵面只是倾角发生变化时,绝对涡度的垂直分量守恒。
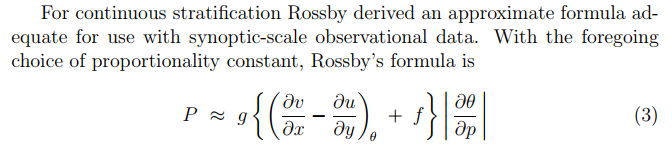
Ertel的位涡公式(1942年),用了三维的涡度矢量,位温的三维梯度。在静力平衡、垂直运动可以忽略的情况下,Ertel公式与Rossby的位涡公式类似。在准地转位涡等相比较时,这两个公式的计算结果一般都被当成是精确的位涡
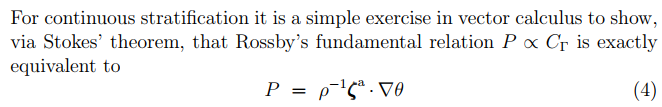
Ertel的位涡公式的变形,用于验证位涡在无耗散流中是守恒的

稳定大气的PV逆算子
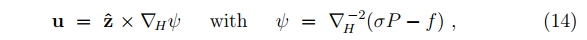
准地转位涡公式( 最简单但最不精确。首先只保留了水平风速,尽管此时垂直运动很明显;其次,遗弃了有垂直输送和水平输送的精确的Rossby-Ertel PV,引入了一个只有水平输送的准地转PV)

参考资料
- http://www-das.uwyo.edu/~geerts/cwx/notes/chap12/pot_vort.html
- https://www.researchgate.net/publication/333740766_Explosive_Cyclogenesis_around_the_Korean_Peninsula_in_May_2016_from_a_Potential_Vorticity_Perspective_Case_Study_and_Numerical_Simulations
-
两组大样本的均值ttest检验
python均值检验函数
ttest检验原理公式

pytho的显著线检验一般都使用SciPy程序包,当检验两组样本均值时,有如下几种方法:
from scipy import stats import numpy as np tvalue,pvalue = stats.ttest_ind_from_stats(mean1, std1, numb1, \ mean2, std2, numb2, equal_var=True, alternative='two-sided') # 输入两组数据的均值、方差和样本量以进行显著性检验 # equal_var=True表示两组数据具有相近的总体方差(默认) # 若False,表示两组数据不具有相近的总体方差 # 一样的输入,若equal_var=True,则得到的pvalue偏小,更容易通过显著性检验 tvalue,pvalue = stats.ttest_ind(data1,data2, axis=0, equal_var=True,\ nan_policy='propagate', permutations=None, random_state=None, \ alternative='two-sided', trim=0) # 也是用于检验两组样本均值是否显著差异,但该函数需要将两个样本全部输入, # 若样本量较大,则比较占用内存,因此个人还是更喜欢上面那个函数 # 关于各参数的具体介绍可以看 # https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html # 此外 SciPy 也有提供检验两组样本总体方差是否相等的函数levene与bartlett # 输出统计值和pvalue,当pvalue大时,说明两组样本的总体方差差异大 # 相同的两组数据,bartlett的pvalue大于levene的 print(stats.bartlett(data1, data2)) print(stats.levene(data1, data2)) siglvl = 0.05 # 95% 显著性水平 var.values=np.ma.array(var.values,mask=(pvalue>siglvl)) mask = np.array([pu>siglvl,pv>siglvl]).all(axis=0) uwnd.values=np.ma.array(uwnd.values,mask=mask) vwnd.values=np.ma.array(vwnd.values,mask=mask)
-
Matplotlib画布
每张画布只有一个Figure,而一个Figure可以包含多个Axes对象。一个axes对象即一个子图,这个对象包含大量的子元素,包括线条、文本、坐标轴复合对象等等。之所以和Figure进行分离的原因是,Figure用来控制尺寸等一些和元素无关的属性。Axes则用来管理内部的元素。通过Figure.add_axes()可以创建一个axes。或者,直接调用fig,ax = plt.subplots(n)一次创建这两个对象。
第三个重要的层是x(y)axis,这个层也是一个复合对象(实际上是mpl.axis.Axis和mpl.axis.Tick两个类),包含X或者Y轴的元素,包括刻度(Ticks)、刻度文字(Tick Labels ; Offset text),轴标签(Axis Label)等。这一层用来控制图形的尺度,比如x/ylim用来控制坐标轴范围。比如xlabel用来设置label的一些属性,比如字体大小、旋转、颜色、背景和透明度等。
当调用plt.plot()方法的时候,如果系统没有检测到存在Figure对象和Axes对象,则会创建一个,如果检测到,则直接使用。
对于想要重新画一幅图,而不是将图形绘制在一个Figure中并且区分成几个subplot,直接使用plt.figure()创建一个新的Figure对象,使用plt.gcf()也可以捕获这个对象。
每个图形可以有很多子图形构成,每个子图形只有一个Axes,它们可以共享坐标轴,每个子图形都有其各自的AxesSubplot子轴,包含在总的Axes中。
使用plt进行绘图固然很方便,但如果需要细微调整,则不太方便。调用axes单个元素可以获得更精细的控制,并且更面向对象一些。
import matplotlib.pyplot as plt import numpy as np x = np.arange(0.1, 4, 0.5) y = np.exp(-x) #几种创建图形 Fig 和 Axes 的方法 fig = plt.figure(figsize=(12,9),dpi=100) axe = plt.axes(projection=cart_proj) fig = plt.figure(figsize=(12,9),dpi=300) axe = fig.add_axes([0.05, 0.05, 0.9, 0.65]) # 括号中列表指定了该Axes对象的左下角的x、y值、长dx,高dy fig = plt.figure(figsize=(12,9),dpi=100) axe = plt.subplot(1,2,i+1,projection=cart_proj) # 创建一行两列子图 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True) # 返回的ax是一个图形列表 fig, ((ax1,ax2,ax3),(ax4,ax5,ax6),(ax7,ax8,ax9)) = plt.subplots(3,3) print(ax) # plot the linear_data on the 5th,8th subplot axes ax[2][2].plot(x,y, '-') ax[1][1].plot(x,y**2, '-') # 对于一个包含多个轴的fig,可以使用 gcf().get_axis,或者直接对矩阵进行索引和操纵 for ax in plt.gcf().get_axes(): for label in ax.get_xticklabels() + ax.get_yticklabels(): label.set_visible(True) # necessary on some systems to update the plot plt.gcf().canvas.draw()参考资料:
-
python日期与时间的处理函数
time & calendar
关于时间的处理,和ncl很不一样的是,Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间,想处理成任何格式的日期都可以。
python中的日期有两种类型:
- 时间戳 timestamp:以自 1970 年 1 月 1 日午夜(历元)后经过的浮点秒数来表示。某些编程语言(如Java和JavaScript)的timestamp使用整数表示毫秒数,这种情况下只需要把timestamp除以1000就得到Python的浮点表示方法。使用timestamp的好处在于,其值与时区无关。timestamp一旦确定,其UTC(Universal Time Coordinated)时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以timestamp表示的,因为全球各地的计算机在任意时刻的timestamp都是完全相同的(假定时间已校准).
- 时间元组:time.struct_time(tm_year=2016, tm_mon=4, tm_mday=7, tm_hour=10, tm_min=28, tm_sec=49, tm_wday=3, tm_yday=98, tm_isdst=0),一共9组数字,分别表示年、月、日、小时(0~23)、分钟、秒、一周第几日(0~6,0是周一)、一年第几日(1~366)、是否为夏令时(1夏令时、0不是夏令时、-1未知,默认-1)
import time # 格式化成 2016-03-20 11:45:39 形式 print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) # time.localtime([secs])可获得当前时间的本地时间元组,也接受时间戳,并返回当地时间下的时间元组 # time.strftime(fmt[,tupletime])只接收时间元组,并返回以字符串表示的时间 # 将格式字符串转换为时间戳 a = "Sat Mar 28 22:24:24 2016" print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y"))) # time.strptime(str,fmt)根据fmt的格式把一个时间字符串解析为时间元组 # time.mktime(tupletime) 接受时间元组并返回时间戳 time.sleep(secs) # 推迟调用线程的运行,secs指秒数。 time.process_time() # 返回当前进程执行 CPU 的时间总和,不包含睡眠时间。由于返回值的基准点是未定义的,所以,只有连续调用的结果之间的差才是有效的。 calendar.isleap(year) # 是闰年返回 True,否则为 false。 calendar.leapdays(y1,y2) # 返回在Y1,Y2两年之间的闰年总数。pandas的date_range
pandas的
pd.date_range(start*, end*, periods*, freq)函数可以生成任意间隔的时间序列。带*的参数表示可选参数- freq参数由数字和英文(M月,D天,H小时,Min分钟…)组成。如20D表示间隔20天,5M表示间隔5个月
- start和end日期字符串,可以是”20171011”,”2021-09-25”,”1/30/2018”
- periods生成数据的时间长度,因此可以通过只给定 start和periods生成时间序列。
举例如下:
import pandas as pd ftime = pd.date_range(start='2021-09-25 00',end='2021-09-25 12', freq='1H' \ ,closed=None).strftime("%Y-%m-%d_%H:00").to_list() ''' 若没有后面转换格式的命令.strftime("%Y-%m-%d_%H:00").to_list(),得到的结果如下: DatetimeIndex(['2021-09-25 00:00:00', '2021-09-25 01:00:00', '2021-09-25 02:00:00', '2021-09-25 03:00:00', '2021-09-25 04:00:00', '2021-09-25 05:00:00', '2021-09-25 06:00:00', '2021-09-25 07:00:00', '2021-09-25 08:00:00', '2021-09-25 09:00:00', '2021-09-25 10:00:00', '2021-09-25 11:00:00', '2021-09-25 12:00:00'], dtype='datetime64[ns]', freq='H') '''datetime
datetime是Python处理日期和时间的另一个标准库,pd.date_range(start, end, periods*, freq)生成的时间就是这个格式的。 字符串与datetime之间的相互转换和time模块类似
from datetime import datetime, timedelta, timezone now = datetime.now() # 获取当前datetime print(now.strftime('%a, %b %d %H:%M')) # 将datetime以自定义格式转换为字符串打印 dt = datetime.strptime('2015/6/1 18:19:59', '%Y/%m/%d %H:%M:%S') # 把str转换为datetime,只能一个时间一个时间地转换 dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime # print得到的结果会是 2015-04-19 12:20:00 print(dt.year) # 也可以单独查看 month, day, hour, minute, second, microsecond, tzinfo # 但无法通过dt.hour=13修改datetime的时间,只能通过timedelta对日期时间进行加减,得到新的时间 now = datetime.now() # 获取当前datetime a1 = now + timedelta(hours=10) #时间向后推移10个小时 a2 = now - timedelta(days=1) #日期向前推移1天 # 也可以通过两个时间点相减,获得总的时间间隔秒数 dt1 = datetime(2015, 4, 19, 12, 20) dt2 = datetime(2015, 4, 21, 12, 20) (dt2-dt1).total_seconds()/60.0/60.0 #间隔的小时数 dt.timestamp() # 把datetime转换为timestamp dt = datetime.fromtimestamp(time.time()) # 把时间戳转为本地时区的datetime dt = datetime.utcfromtimestamp(time.time()) # 把时间戳转为UTC的datetime对于nc文件的时间轴
以ERA5为例,其时间坐标是以自1900年1月1日午夜零时以来的小时数表示,和python的时间戳不一样。
int time(time) ; time:units = "hours since 1900-01-01 00:00:00.0" ; time:long_name = "time" ; time:calendar = "gregorian" ;当用 xarray.open_dataset 打开nc文件读取时间维,好像是会自动将该时间坐标转为datetime.
但若是用netCDF库的Dataset打开nc文件,则需要使用 num2date 将时间坐标转为python时间戳(根据ECMWF给出的python例子),如下所示:from netCDF4 import Dataset, date2num, num2date with Dataset(f_in) as ds: var_time = ds.variables['time'] time_avail = num2date(var_time[:], var_time.units, calendar = var_time.calendar) ''' print(var_time) 的结果: <class 'netCDF4._netCDF4.Variable'> float64 time(time) standard_name: time units: hours since 1994-12-01 00:00:00 calendar: proleptic_gregorian unlimited dimensions: time current shape = (10248,) filling on, default _FillValue of 9.969209968386869e+36 used print(time_avail)的结果: [cftime.DatetimeProlepticGregorian(1994, 12, 1, 0, 0, 0, 0, has_year_zero=True) cftime.DatetimeProlepticGregorian(1994, 12, 1, 1, 0, 0, 0, has_year_zero=True) ... cftime.DatetimeProlepticGregorian(1996, 1, 31, 22, 0, 0, 0, has_year_zero=True) cftime.DatetimeProlepticGregorian(1996, 1, 31, 23, 0, 0, 0, has_year_zero=True)] ''' import xarray as xr ds = xr.open_dataset("ERA5_NH_t_1989.nc") t = ds['time'] ''' print(t)的结果: <xarray.DataArray 'time' (time: 1460)> array(['1989-01-01T00:00:00.000000000', '1989-01-01T06:00:00.000000000', '1989-01-01T12:00:00.000000000', ..., '1989-12-31T06:00:00.000000000', '1989-12-31T12:00:00.000000000', '1989-12-31T18:00:00.000000000'], dtype='datetime64[ns]') Coordinates: * time (time) datetime64[ns] 1989-01-01 ... 1989-12-31T18:00:00 Attributes: long_name: time ''' # 挑选特定时间段的数据 # 方法一:使用datetime from datetime import datetime strt=["1989120206","1989120312"] tim=[] for str1 in strt: tim.append(datetime.strptime(str1, '%Y%m%d%H')) var = ds['t'].sel(level=250,time=tim) # 方法二:使用isin,生成逻辑数组 stime = np.array([ds.time.dt.year.isin([1989,1981]), ds.time.dt.dayofyear.isin([185,186,187])]).all(axis=0) var= ds['t'].sel(time=stime)由于用 xarray 打开 netcdf 文件得到的时间维是一个元素类型为 datetime64[ns] 的 xarray.DataArray 数据,因此无法直接使用 strftime(“%Y-%m-%d_%H:00”) 将其转换其他格式的时间字符串。
此时可以使用 np.datetime_as_string(ds.time) 将其转换为字符串元素的 numpy.ndarray,然后用 pd.to_datetime() 将其转换为 pandas 的数据类型,具体如下:from datetime import datetime time = pd.to_datetime(np.datetime_as_string(ds.time,unit='h'),format='%Y-%m-%dT%H') # 如果只转换一个时刻 str_time = datetime.strptime(np.datetime_as_string(var.time[0]), '%Y-%m-%dT%H:00:00.000000000').strftime('%b %d')matplotlib.dates
当时间坐标轴用 datetime.datetime 列表、pd.date_range 生成的数组表示时,plt中均有函数可以设置横纵坐标的时间格式,示例如下:
import matplotlib.dates as mdates from datetime import datetime import pandas as pd ftime = pd.date_range(start='2021-09-16 00',end='2021-09-16 23',freq='1H',closed=None) ftime = [] for nt in ftime.append(datetime.strptime(nt,'%Y-%m-%d %H:00:00')) # datetime一次只能处理一个变量,不能用于列表和数组 axe.plot(ftime, var, label=case[nc], linewidth=2) axe.tick_params(axis='both', which='major',labelsize=label_font) axe.xaxis.set_major_formatter(mdates.DateFormatter("%m-%d_%H:00")) plt.setp(axe.get_xticklabels(), rotation=30, ha="right")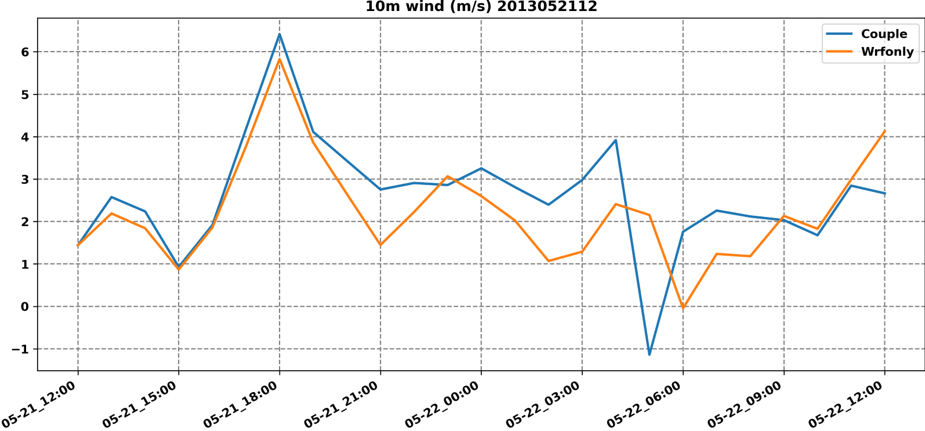
参考资料:
- https://www.runoob.com/python3/python3-date-time.html
- https://pandas.pydata.org/docs/reference/api/pandas.date_range.html
- https://blog.csdn.net/qq_36387683/article/details/84766610
- https://www.liaoxuefeng.com/wiki/1016959663602400/1017648783851616
-
shell的文本操作
在用shell脚本批处理文本文件时,可能需要读取或修改ascii文件中的一些信息。在shell中有许多可以处理文本文件的工具,配合正则表达式,可以实现很多功能。现罗列如下:
- grep 适合单纯的查找或匹配文本,也常用于搜索文件
- sed 主要用于编辑文本,但也可以用于搜索
- awk 适合对格式化文本进行搜索判断,可以对文本进行较复杂格式处理
上述命令的一些常见用法:
# 统计文本文件中某单词出现次数 cat tr_trs_pos.txt | grep -o "TRACK_ID" | wc -l # 竖杠表示管道命令,将前一命令的结果作为下一个命令的输入 # grep -o 表示搜索文本并只显示匹配的部分 # wc [-clw][文件…]可以统计文件(如果没有指定文件,则会从标准输入读取数据) # 的字符数(-c),字数(-w),行数(-l),这里就是只统计行数 # 统计文件中每一个单词出现的次数,并按照出现频率从大到小排序 sed 's/ /\n/g' file.txt | sort | uniq -c | sort -nr # 使用sed读取file.txt文件中的所有内容,并将空格替换为换行符,然后将修改后的内容向sort输入 # sed 在不使用 -i 参数时,是不会直接将文件里的内容修改,因此此时file.txt里的内容不会被修改 # sort可以将文本内容加以排序,-n表示按照数值大小排序,-r表示以相反的顺序排序 # uniq 检查并删除文本中重复出现的行列,-c或--count 在每列旁边显示该行重复出现的次数。 # 重复的行并不相邻时,uniq 命令不起作用,因此需要先 sort sed -i "34s/.*/${fras}/" STATS.latlng_1hr.in # 将文件中第34行的内容替换为变量fras存储的内容 awk '{if(NF==4 && ($2 > 400 || $3 > 100 )) print FILENAME, $0}' $filname | awk 'END{print NR}' awk 'NR==4 {print FILENAME, $2}' file1.txt | tee -a file2.txt # 查看文本文件第一列的去重信息 awk '!seen[$1]++' hg38.all.cpgSite.bed # 输出第一次遇到的第一列,而忽略后续的相同项 awk '{ print $1 }' hg38.all.cpgSite.bed | uniq # 去重,若后面加-c,则会显示每一个元素的重复次数, 但重复行不相邻时,该命令不起作用 awk '{ print $1 }' hg38.all.cpgSite.bed | sort -u # 对第一列去重并排序 # 将文本文件按第一列特定字符串及第二列排序 sort -k 1,1V -k 2,2n ${file} | awk '{ if($1=="chr1"||$1=="chr2"||$1=="chr3"||$1=="chr4"||$1=="chr5"||$1=="chr6"||$1=="chr7"||$1=="chr8"||$1=="chr9"||$1=="chr10"||$1=="chr11"||$1=="chr12"||$1=="chr13"||$1=="chr14"||$1=="chr15"||$1=="chr16"||$1=="chr17"||$1=="chr18"||$1=="chr19"||$1=="chr20"||$1=="chr21"||$1=="chr22"||$1=="chrX"||$1=="chrY") { print } }' > ${file}.sort # -k 1,1V: 指定按照第一列进行排序,-k1,1 表示只考虑第一列,V 表示按照版本号进行排序(版本排序,例如,10会排在2的前面而不是后面)。 # -k 2,2n: 如果第一列相同,则按照第二列进行数值(numeric)排序,-k2,2 表示只考虑第二列,n 表示按照数值进行排序。 # 详细解释可以参照该网站 https://www.cnblogs.com/51linux/archive/2012/05/23/2515299.html